When I first started as a developer, the process was simple. You picked (or were assigned) a bug to fix, you fixed it, and then you sent it off for testing.
…and then, sometimes, your tester (another developer) argued that you’d fixed the bug in entirely the wrong way and should completely redo the fix. Sometimes he also provided information you didn’t know about that proved he was definitely correct.
Then we added a design requirement. Before doing a fix, you had to have another developer sign off on what you were going to do, which meant that many potential problems could be uncovered before putting in too many hours of work.
Of course, it wasn’t always that easy. Sometimes you don’t have any idea how to fix a problem until you’ve spent a while working on it, and sometimes you just have to sit down and code a solution before you know whether it’ll work or not. But overall, adding a design step to the process made it flow a lot more smoothly, even taking the additional design time into account.
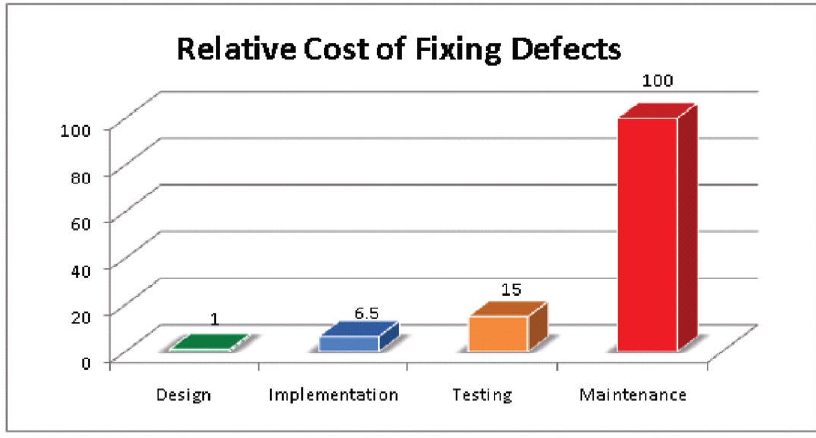
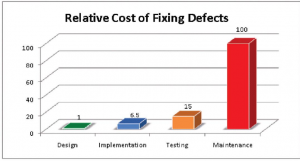
No doubt you’ve seen infographics similar to this one:
Integrating Software Assurance into the Software Development Life Cycle (SDLC) (PDF Download Available). Available from: https://www.researchgate.net/publication/255965523_Integrating_Software_Assurance_into_the_Software_Development_Life_Cycle_SDLC [accessed Jun 21, 2017]
The idea is simple: the earlier a problem is found, the easier it can be fixed. It’s easy to move lines around in a blueprint; it’s much more difficult to move the walls in a finished building. Similarly, it’s best to get input from all the stakeholders as to whether your proposed fix meets their needs before you actually spend a lot of time implementing and testing it, especially if it takes a while for new development to make it through the testing process. We actively solicit feedback from end users before a new feature is complete, because we want to know how it meets their needs while we’re still building, not a year later when we’ve moved on to other things.
Of course, it’s also easy to go too far. A design shouldn’t be a copy of all the code changes you’re making (unless it’s a really simple change); in that case you’re still doing the development first and getting feedback later. At the same time, it should usually be more detailed than “there’s a bug in this part of the code and we’re going to fix it.” At minimum, as a person reading your design, I should understand:
What is the problem?
How are you doing to fix it?
How will I know it’s been fixed?
For example, a design might be something like:
When you do X, the software crashes.
This happens because we didn’t check for a null property before accessing a subproperty, in this function.
Pretty straightforward, right? But it’s clear what the problem is (the software crashes), what the developer is going to do about it (add a null check), and what the result will be (the software will no longer crash). The technical reviewers understand what the fix will be and can suggest changes (should we be showing an error message if that property is null?). The testers understand the workflow they have to follow to reproduce the crash (or rather, to not reproduce it). And the poor developer doesn’t have to make the fix, test it, send it off for code review, and then be told to do something completely different. Everybody wins!
As programmers, we tend to do what we do for two main reasons: to build something cool, or to draw a paycheck. Those paychecks tend to be pretty decently sized, because we create a lot of value for the companies we work for. But how is that value quantified?
To an employer, value is probably quantified financially: are we generating more income than the cost to keep us on? This is why (I’ve read – I don’t have personal experience here) developers at a company that makes and sells software get treated better than developers making software for internal use only at a non-software company; the first group are revenue producers, while the second are operating expenses.Creative Commons by CheapFullCoverageAutoInsurance.com
The trouble is, it can be difficult to find a direct link between much of what we do and how much money is coming in. If I spend a week writing unit tests and refactoring code to reduce technical debt, I haven’t created anything new that we can sell, nor have I done anything that will let us increase the cost of our product. From a strictly code->dollars perspective, I haven’t done anything productive this week.
So if we’re not directly creating value for our company, are we creating value for our customers? By refactoring the code, I’m making it easier to add new features in the future, features that will help to better meet customers’ needs. When we create software that meets customers’ needs and wants, we are providing value. But how do we quantify this? If we have a good way to estimate the size of a new feature, then one way would be to measure how long it takes the implement the feature and how many bugs are produced; if these numbers decline over time, then either we’re getting better at developing (and thus our personal value to the company has increased) or we’ve improved our processes (or, in this case, the codebase we’re working with). So one measure of value would be the amount of (relatively) bug-free software (in terms of small, medium, large, or very large features) we can provide in a given increment of time.Creative Commons BY-SA 3.0 Nick Youngson
Of course, not all features are created equally. In an ideal world, we would be able to have our customers put a dollar value on each thing we might spend time on (a new feature, a 10% reduction in bugs, etc), sort those items to find the ones with the highest value per increment of time, and do those first; in that way we could be sure of providing the maximum amount of value. In practice, customers naturally don’t care about things like that refactoring that don’t pay off immediately but make all the other stuff easier in the long run.
So how do you quantify value in software development? I don’t think you can put a value on any given hour’s activity; software development is too much of a creative process in which one thing affects too many others. In the long run, it comes down to a binary: are we able to give our customers what they want and need at a price they’re willing to pay? If so, we’re providing them the value they desire and earning those paychecks.ommons
I heard a phrase I liked recently: software testing is ensuring goodness. [Alexander Tarlinder on Software Engineering Radio]
How do we ensure that our software is good, and further, what does good even mean? For a first approximation, let’s say that good software does what it’s supposed to.
How do we define what the software is supposed to do? That could mean it does what the design says it does, that it does what the user wants, or that it does what the user actually needs. This gives us the first few things to test against: we check that the design accurately reflects the users’ wants and needs, and that the software accurately reflects the design.
Of course, there’s a lot involved in writing software that isn’t generally covered in the design. Ideally we’ve specified how the program will react to any given class of input, but in practice users tend to do things that don’t make any sense. I had a bug recently that only appeared if the user opened a section of the page, clicked on a table row, opened a second section, opened a third section, hit the button to revert all the changes, reopened the third section, and then clicked a row in that section. There was certainly nothing in the design stating that if this particular sequence of events was to happen, the activity would not crash!
Ok, so that’s reaching a bit – of course we assume that the software shouldn’t crash (provided we’re not making a kart racing game). The design covers the expected responses to user stimuli, but we assume that it will not crash, freeze up, turn the screen all black, etc. Unfortunately, for a non-trivial piece of software the number of possible things to try quickly becomes exponential. How do we ensure that we’ve tested completely enough to have a reasonable chance of catching any critical bugs?
Finding the Bugs
Photograph of a mantis shrimp. Public domain, National Science Foundation.At some point, we have to determine how much effort to put into finding (or better yet, avoiding) bugs in our software. The more mission-critical the program is, obviously, the more time and money it’s worth investing into finding bugs and the less disruptive a bug has to be to be worth finding and fixing.
I’m a strong believer in the value of having a separate, independent quality assurance team to test the software. Testing is a completely separate skill from coding – rather than trying to build software that works, you’re trying to find all the ways that it could possibly break. So I think it’s valuable to have people skilled in the art of creative destruction, who can approach the software from the perspective of the end user, and who have the authority to stop code changes from moving forward if they believe those changes to be damaging to the quality of the code.
At the same time, there’s no guarantee that a few QAers will be able to try all the weird things that thousands of users might do once your software is out in the wild, which is why we also need code review (or PQA, programmer quality assurance). In code review we have a better chance of catching the one-time-in-a-million bugs that will never show up in testing and yet, somehow, will always pop up in the released code. One of the senior developers on my team was really good at this; I hated having him review my code because I knew he would nitpick every little thing, but I would still choose him to do PQA on my development for the same reason – he was really good at finding anything that might end up being a problem.
How to not code bugs
Speaking for myself, I’m not a fan of doing PQA – it gets boring really fast. Ironically, the better the code is the more boring PQA can be: with the junior developers there tends to be a lot of things you can make suggestions on, but when the code you’re looking at is very well done, you can spend an awfully long time examining it without finding anything wrong, and it takes an effort to get more in depth and concentrate more on finding subtle logic errors and race conditions rather than correcting bad habits and obvious errors in less developed code. Not that you don’t look for the subtle errors in the less developed code too, of course, but you’re not spending an hour looking through the code without finding anything.
On the other side of that, of course, you want to be the person writing the code where your PQAers can’t find anything to complain about. I have not yet figured out how to do this – not even close – but there are a few things that help.
Testing. Ok, this one is obvious, but it can be surprising how often someone makes a very minor change and then doesn’t go back and test afterwards. Even a change that can’t possibly break anything, often does.
Following standards. My team has a set way of doing things, and yours probably does as well. Why? Because we’ve broken stuff in the past, and figured out how to not break them the same way in the future.
Refactoring. See below.
So we’ve been doing unit testing for about the last year and a half, now. Most of the unit tests so far are in code that hasn’t really been updated a lot since the tests were written, so they aren’t yet serving one of the primary purposes of unit tests: letting the next person to work on your code (who might be you) know if he breaks it. What they are doing is making the code better.
When I’m writing unit tests for a function, sometimes I run into problems:
It’s not obvious what the function is doing. This generally means that the function (and possibly some parameters) needs to be renamed so that it’s very clear what will happen when it’s called.
The function is doing too much. In this case, I split it up into multiple functions – even when the subfunctions will only be called from one place. This gives me several functions that only do one thing, which makes it easier to verify that the logic behind each piece of functionality is correct.
The function depends on something being set prior to being called (generally uncovered by a crash when the unit test first calls it with no prep work). This is a good time to verify that under no circumstances can the function ever be called without its prerequisites ever being set (and possibly document the preconditions).
The function contains logic which is actually wrong. In this case, I’ve just uncovered a bug, and can fix it, before my code goes to testing.
Most of the time when I’m refactoring a function there aren’t actually any bugs present, yet… but conditions exist that make it easier for bugs to be inserted. By cleaning up the code, I then improve my chances of being able to make changes without introducing new bugs in the code. Further, because the code is now easier to read, not only are future changes less likely to break it but they’ll be made faster and with less frustration.
So how do we ensure goodness? Very carefully, I suppose. In my experience, the best way to do this is just to make it easy to do the right thing. Make it clear from the names what functions do, keep the code as simple and straightforward as possible, and be sure you understand exactly what the code is doing before you make changes (or, if you’ve written it, before you commit it).
Of course, having a can of RAID on hand never hurts.
One of the disadvantages of doing web development (to me, anyway) is that I don’t often get to use my background in theoretical computer science, especially with the front end stuff. It’s much more likely that I’ll be fighting with javascript than calculating asymptotic runtimes!
A few weeks ago was an exception. We had a number of jobs what could be scheduled and needed the software to determine, when a user made a scheduling request, whether that request could cause either the job being scheduled or any job that depended on it to exceed the time allowed. This was a fun little problem that I solved by using a modified depth-first-search to find the longest dependency chain for each job, then using the depths obtained in this preprocessing step to efficiently [O(n+m)] determine which jobs, if any, would end up running past the allotted time so that we could warn the user before allowing the scheduling.
Tools. Image is in the public domain.
In this case, the problem instance is generally small enough that we could have just brute forced a solution and it would likely still have had a reasonable runtime, but going with an efficient solution straight off means we don’t have to worry about scaling this up in the future, and the code is just nicer to work with.
You often see knowing the standard algorithms being compared to having more tools in your toolbox, and I think that’s a good comparison. I’m not the super-handyman type, but I still keep a good set of power tools around, and when something around the house needs to be fixed I often have the tools I need to just go ahead and take care of it, and I don’t have to force a tool into a situation it’s not meant for because I don’t have the correct tool available. Similarly, some types of development may not require you to pull out the graph algorithms all that often, but when those situations arrive they’re helpful to have around.