Recently my friend Janie has done a series of blog posts on her disagreement with using computer science questions as a major part of the hiring process. I can agree with her, to a point.
If you’re hiring for someone to do a specific job using a specific language or framework, and the person being interviewed can demonstrate experience with and competence in that language or framework, then that’s probably as far as you need to go. You have a job that needs to be done and you’ve found someone who can do that job. Win!
I think that when the job is less well-defined is when algorithms questions can more usefully come into play. But let me back up and relate a few stories from my personal experience.
As a GTA (graduate teaching assistant) part of my job was to monitor the computer lab and help people as needed. The undergraduate classes at my school used Java; I don’t, but I grabbed a book and picked up enough of it to be able to get people unstuck. I guarantee that pretty much everyone I helped had much more experience with and knowledge of Java than I did – they were using it every week for their classes, while I’d picked up the bare minimum to be able to read it. But I was getting people unstuck because they didn’t understand how to take a problem and write a program that would solve it; they knew how to program, but they didn’t know how to think.
The class that I taught, Foundations of Computer Science, involved no programming whatsoever (and many people put off taking it, for that reason). We covered finite state machines, regular expressions, Turing completeness, that sort of thing. I can recall thinking that if I was hiring someone for just about any job, I would consider an A in that class as a strong recommendation, because it meant that you could think logically and solve problems.
When I was working on my PhD I did almost no programming; I was focused on theory. I think I wrote three programs in four years. Towards the end of that, Microsoft was doing interviews on campus, and I decided to give it a try; the interview turned out to be two questions along the lines of “Here’s a problem. Solve it, then find the fastest possible solution.” I found the problems to be reasonably straightforward (though you had to be a little creative for one of them) but the interviewer told me that most of the people he’d interviewed couldn’t even answer the first problem.
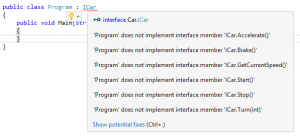
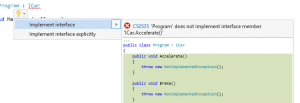
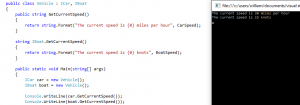
I don’t mean to suggest here that programming skills or experience are not important, only that unless the problem is very well defined, they may be less important than knowing how to figure things out. The advantage that knowing algorithms (and everything that goes with it) gives you is that you have more tools available to you; in the case of the Microsoft questions, one of the problems was very obviously susceptible to dynamic programming, and knowing big-O analysis made it easy to say “this is the best asymptotic runtime of any solution to this problem.”
My current employer has a similar philosophy. The initial test I took allowed you to use any programming language you liked; another one taught you an obscure language and then asked you to use it. Combined with a preference for people with strong academic backgrounds, they’re selecting for employees with a demonstrated ability to both solve problems efficiently and pick up new things quickly. Now I regularly use half a dozen languages at work, none of which I knew when I started, and the turnover at the company is low compared to the larger tech industry. Microsoft and Google have actually pouched half of my team over the last few years, but that’s another story..













{kind=link}