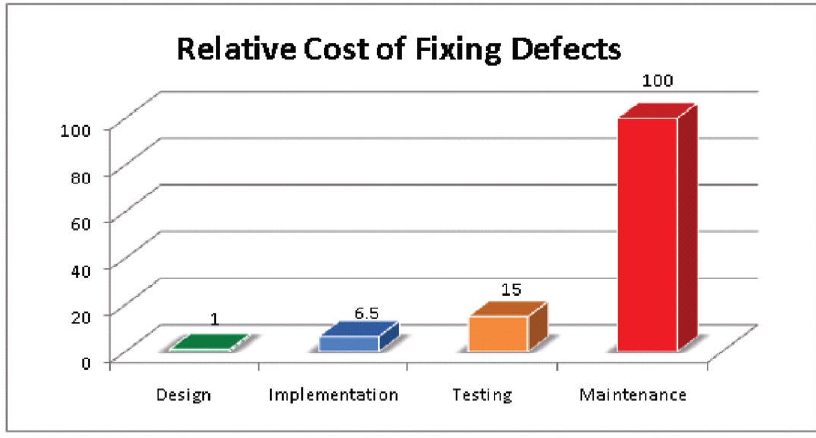
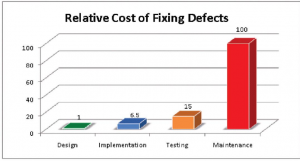
Some little details cause trouble entirely disproportionate to their importance. One such thing is a little quirk in how Oracle handles indexes.
I have some code which gets a list of tables using a particular criteria and then gets all of the indexes associated with those tables. Under normal circumstances, the code works fine. However, when testing in a clean database, it will completely fail to find any of the associated indexes, even though they’ve been verified to exist.
…or have they? It turns out that when the corresponding table does not contain any data, the index may still be associated with the table but it doesn’t really exist. So when you run a query like this:
select * from dba_indexes ind
join dba_segments s
on ind.index_name=s.segment_name
where ind.table_name=’MYTABLE’
It returns no results. Cue confusion. Adding a row to the table causes the index to actually be created and allows my script to start working correctly.
One problem I had this week is that a piece of code which had, for the previous few years, been perfectly behaved suddenly started crashing for a new customer. This was the first time I’d seen the code run on a Finnish system, so a problem with internationalization seemed like the obvious place to start.
Running the software on a fi-fi system, I found that a call to Double.Parse was causing a FormatException: Input string was not in the correct format.
The issue here was that the code was attempting to parse a string which contained a software version number, e.g., “2005.100”. In a US English environment, this works fine – that gets parsed as 2005.1. In a German environment, this works fine – that gets parsed as 2005,100. Finnish, however, doesn’t use the period as either a decimal separator or a thousands separator, so when the system tried to parse the string, it didn’t recognize it as a number.
The solution is to pass in the second parameter for Parse, which (at least in C#) is an IFormatProvider. When no IFormatProvider is given, the system defaults to InstalledUICulture, which means it was trying to interpret the string according to the system’s locale settings. By passing in InvariantCulture, I force it to ignore the locale settings and interpret the input as an English (no country) string.
As a result, this value – which is always stored in the same format – is also always read in the same format, and the end user sees the same behavior regardless of the computer on which the code is being run.
This week I ran across a new-to-me option in some T-SQL code I was reviewing: OPTION (RECOMPILE). It turns out that this option improves performance by forcing SQL Server to recompile the query rather than using the plan it already generated.
Wait, what? Don’t we save time by saving a query plan and reusing it?
Generally, yes. When you first run a stored procedure, the SQL engine will figure out a plan for that procedure and cache the plan for reuse, thus saving the time of recomputing the it each time the procedure is run. The problem comes in when a plan is generated that makes sense for the current database state and parameters, but doesn’t make sense when those change. For example, suppose you have a table with ten million rows; different approaches are required if you want to retrieve ten of those rows vs seven million of them.
Generating the query plan
When the stored procedure is executed, SQL Server looks at the distribution statistics it has about the data in the tables the procedure references and uses this data to guess at the best way to run the query. Assuming that the statistics are up to date, it can generally make a fairly good guess; for example, it may choose an index seek if it expects to return a small number of rows, but a table scan if it expects that a significant percentage of the table will be returned.
Parameter sniffing
Sometimes, the output of the procedure depends heavily on the value of a parameter; one value might result in returning one row, while another returns a million rows. When you run the procedure, SQL Server sniffs the parameters and uses whose to choose the query plan. If a query is called with literal values, you get one plan for each call, but if it is parameterized, the same plan is used the next time the procedure is called even if the value of the parameter is very different. If the procedure behaves similarly as the parameter varies, this works fine, and you save the cost of creating a new plan each time. If it doesn’t, however, you can end up with a plan that is orders of magnitude slower than optimal.
Recompiling
Telling SQL Server to recompile forces it to create a new query plan rather than reusing the old one. When the old plan was “good enough”, this is a bad thing – generating the plan is expensive. In some cases, though, the performance improvement from using a better plan easily overwhelms the cost of recomputing that plan.
One way to do this is to alter the stored procedure to include the WITH COMPILE option; this tells SQL Server not to cache a plan, so the query plan is regenerated each time. Alternatively, we can add OPTION (RECOMPILE) at the statement level, in which case only the plans for that particular statement, rather than the entire procedure, will be regenerated.
Being bossy with SQL Server
Forcing a recompile isn’t the only way to take control away from SQL Server. Another option is to use the OPTIMIZE FOR hint, when you know that the plan for a particular value will work well for a wide range of possible parameter values; in this case, you use domain knowledge to improve on what SQL Server could manage with statistics alone. You can also use OPTIMIZE FOR UNKNOWN to keep SQL Server from optimizing based on the particular value that was passed in.
Remember the disadvantages of taking control away: you lose the performance benefits of reusing a query plan, and if you make a bad choice as to what value to optimize for (or the data changes to make it a poor choice), you could see much worse performance than if you just leave SQL Server alone to do its own thing. As usual, you want to tell SQL Server how you want it to process something (rather than just what you want it to do) only when you have a good reason for doing so.
A div for everything and everything is in its div…
If you’ve been working on websites for a while, you’ve no doubt had a few that seem to be just div after div, where the div explosion serves to place or style each part of the page as needed. The problem is, a div by itself doesn’t tell the user (or, more to the point, the user agent) anything about what the div contains, and the styling is likely to be lost on someone using a screen reader.
In HTML5, we have the semantic elements, which generally act like divs – they’re block elements that contain other elements – but also provide meaning; each tag describes what it contains, which allows a user agent (such as a screen reader) to handle it appropriately. We still use divs, when no semantic element is appropriate, but they should no longer be the first choice. The semantic elements include:
<nav> encloses a navigation block; this will often contain a list of links, but not every list of links needs to belong to a nav. Screen readers may be able to go directly to the nav section or skip it if not needed.
<main> is for the main content of the document; it should contain only content that is unique to that document, not content repeated across multiple pages. User agents will often be able to navigate directly to the main content block, bypassing navigation links. At most one main element should exist in a given document, and it cannot descend from an article, aside, header, footer, or nav element.
<article> describes a self-contained block; it could be moved to another page and still make sense on its own. A page that consists of one self-contained block of content will simply hold it inside a <main> element, but multiple blocks that do not depend on each other will be <article>s instead. An <article> can contain other <article>s that are related to it, such as comments on a story.
<aside> contains information which is tangentially related to the primary content, but isn’t required to understand it; this content is likely to be visually represented as a sidebar or pull quote.
<figure> encloses some self-contained content, which may be (but is not required to be) graphical in nature. Each <figure> may contain one <figcaption>, which provides a caption for everything contained in the figure; this groups all of the contents and provides a way to refer to them even if the page layout changes.
<section> is a…er…section of the document; it groups together part of the document, such as a chapter. Sections generally come with headers and should contain content that logically belongs together.
If none of the above signpost elements are appropriate, then we look for a more specific element, such as <address>, <blockquote>, or even <p>. Only if the content doesn’t have any semantics do we use the plain <div>. It’s a bit more work, but it allows the user agent to process each type of content according to its own rules, according to the user’s desires.
The answer, of course, is that a website is accessible if it is usable by all people, regardless of disability. When building a website, however, we need something a little more concrete; we need a way to test whether the website is accessible, without having to have people with a hundred different impairments actually testing it. That’s where the Web Content Accessibility Guidelines (WCAG) from W3C come in. Following the guidelines doesn’t guarantee that your website is usable for everyone, but it’s a good starting point for handling the most common accessibility issues. The guidelines help insure that all users can both access the content and navigate the website.
How important is the WCAG standard?
Many countries require that their government websites follow the WCAG standard (the US uses Section 508 guidelines, which are expected to require AA WSAG compliance, described below). Last month, a federal court ruled that having an inaccessible website is a violation of the Americans with Disabilities Act (ADA), and the Justice Department has successfully sued companies (including Carnival and Wells Fargo) over lack of accessibility (both physical and online). The ADA requires that places of public accommodation be accessible to the disabled, and websites which directly sell goods or services, or connect to physical locations which do, have been ruled to be places of public accommodation and thus subject to the ADA requirements.
How are websites evaluated?
WCAG includes three levels of compliance: A, AA, and AAA. A is the minimum level of conformance; a website that does not meet the level A requirements is simply not usable by people with certain disabilities. These are things that every accessible website MUST do. AA requirements make the website easier to use; these are things that every accessible website SHOULD do. Finally, AAA requirements are going “above and beyond” to make things easier for people with disabilities; they are things that a website MAY do. In order to claim compliance for a particular WCAG level, every part of the website must meet every WCAG requirement for that level (as well as for the levels underneath it).
What is covered?
The WCAG standard is composed of four basic principles, with a number of guidelines that lay out specific requirements for meeting those principles. The principles are:
Perceivable. This is the most straightforward: information must be presentable to the user in a way that he or she can perceive. This includes things like text alternative for non-text content (pictures, recorded audio, recorded video), not communicating information solely by color, allowing the user to resize text, etc.
Operable. This means that a user is able to navigate the website. This includes obvious things like being able to navigate using a keyboard alone, without losing focus, but also things like not having anything that flashes more than three times per second, which could trigger a seizure.
Understandable. This principle at first seems more subjective; who’s to judge whether the text of a website is understandable or not? Guidelines here include that the browser can determine what language the page is in, explaining abbreviations (such as by putting the first use of the abbreviation immediately after the expanded form, as we did with WCAG and ADA above), and making the website perform in predictable ways (for example, having consistent navigation).
Robust. The website can be interpreted reliably by a variety of user agents – this is any piece of software acting on behalf of the user, such as a screen reader. This includes things like closing tags (so that the site can be parsed correctly) and associating labels with their corresponding fields.
Getting started
Because the standards include things like website navigation, the easiest way to meet them is to design in accessibility from the very beginning. Failing that, the guidelines are relatively straightforward to test for, and many of the accommodations, such as providing alt text for images, are fairly trivial to make. Even small changes like this can make a huge difference for someone trying to use your site, and many of them benefit your typically-abled users as well.
One of the things I’ve been working on lately is ensuring that our web apps are accessible, which primarily means that those with visual impairments can use them. Partially that means making sure to use high-contrast colors and large buttons, and partially it means the webpages work well with screen readers.
Screen reader compatibility largely breaks down into the following:
Is the entire page keyboard accessible; can the user access all functionality and information without using the mouse?
Does the screen reader tell the user everything he needs to know about what’s going on on the page?
Does the screen reader avoid throwing gibberish at the user?
Is the page keyboard accessible?
Can all of the page functionality be used without a mouse? This means more than just being able to tab to all fields (although that’s the obvious first step). Other things to consider:
Is there any information that’s only available when hovering over an area of the screen? Unless this is a field that can be tabbed to (in which case a screen reader will read the tooltip), that information may not be available to keyboard users (or mobile users).
If there is a popup window, does focus return to the main page when the popup is closed? Similarly, when clicking a button, does focus go away? If focus is lost, a keyboard user is stuck.
Will all visible information actually be read?
If the page contains text which isn’t associated with a control that can gain focus, it may be ignored entirely by the screen reader.
If taking an action causes a visual change elsewhere in the page – say, making a warning visible – then even if that change is visible to the screen reader, the user is unlikely to know about it immediately and could either miss it entirely or become frustrated when it is encountered and it’s either not clear what caused the warning or it’s difficult to navigate back to the appropriate section.
Will extra information be read?
If you don’t tell them what not to read, screen readers will try to grab everything. Even a well-designed page will throw a lot of information at the user (which is why screen readers talk really fast). If you’re using tables to style your content, the screen reader will read off all the details of the table. When testing, I’ve found that sites like Facebook can completely overwhelm the screen reader. There are various attributes you can add to clean this up (such as role=”presentation”) which may or may not be correctly interpreted, depending on which screen reader you use.
Testing
Unsurprisingly, accessibility ends up being something that, while you can follow best practices, you still need to test for. The top screen reader option, JAWS, is horrendously expensive (starting at $900 for a home license), but NVDA is a free, open source alternative that works well for testing. Helpfully, there is a text box option so you can see what it’s saying rather than simply listening at high speed. So far I’ve only used it for work, but while writing this post I tried it out on this site and determined that the site is not actually screen reader friendly, which tells me I need to make some revisions! Hopefully I’ll have an update on that in a future post.
Is it worth it?
Making a website accessible can be a lot (and I mean a lot) of work, for relatively little reward (the number of people using screen reader software is obviously a small percentage of the overall audience, particularly for some specialized sites). However, we still have an obligation (both moral and, in some cases, legal) to make our work usable for as many people as possible. As a bonus, efforts taken to improve usability for people with disabilities often end up being a great help to people we wouldn’t normally think of as disabled, simply impaired – the elderly, for example, who may have weakening vision. In a future post, we’ll talk about accessibility improvements we can make that will help improve usability for all of our users.
When I first started as a developer, the process was simple. You picked (or were assigned) a bug to fix, you fixed it, and then you sent it off for testing.
…and then, sometimes, your tester (another developer) argued that you’d fixed the bug in entirely the wrong way and should completely redo the fix. Sometimes he also provided information you didn’t know about that proved he was definitely correct.
Then we added a design requirement. Before doing a fix, you had to have another developer sign off on what you were going to do, which meant that many potential problems could be uncovered before putting in too many hours of work.
Of course, it wasn’t always that easy. Sometimes you don’t have any idea how to fix a problem until you’ve spent a while working on it, and sometimes you just have to sit down and code a solution before you know whether it’ll work or not. But overall, adding a design step to the process made it flow a lot more smoothly, even taking the additional design time into account.
No doubt you’ve seen infographics similar to this one:
Integrating Software Assurance into the Software Development Life Cycle (SDLC) (PDF Download Available). Available from: https://www.researchgate.net/publication/255965523_Integrating_Software_Assurance_into_the_Software_Development_Life_Cycle_SDLC [accessed Jun 21, 2017]
The idea is simple: the earlier a problem is found, the easier it can be fixed. It’s easy to move lines around in a blueprint; it’s much more difficult to move the walls in a finished building. Similarly, it’s best to get input from all the stakeholders as to whether your proposed fix meets their needs before you actually spend a lot of time implementing and testing it, especially if it takes a while for new development to make it through the testing process. We actively solicit feedback from end users before a new feature is complete, because we want to know how it meets their needs while we’re still building, not a year later when we’ve moved on to other things.
Of course, it’s also easy to go too far. A design shouldn’t be a copy of all the code changes you’re making (unless it’s a really simple change); in that case you’re still doing the development first and getting feedback later. At the same time, it should usually be more detailed than “there’s a bug in this part of the code and we’re going to fix it.” At minimum, as a person reading your design, I should understand:
What is the problem?
How are you doing to fix it?
How will I know it’s been fixed?
For example, a design might be something like:
When you do X, the software crashes.
This happens because we didn’t check for a null property before accessing a subproperty, in this function.
Pretty straightforward, right? But it’s clear what the problem is (the software crashes), what the developer is going to do about it (add a null check), and what the result will be (the software will no longer crash). The technical reviewers understand what the fix will be and can suggest changes (should we be showing an error message if that property is null?). The testers understand the workflow they have to follow to reproduce the crash (or rather, to not reproduce it). And the poor developer doesn’t have to make the fix, test it, send it off for code review, and then be told to do something completely different. Everybody wins!
As programmers, we tend to do what we do for two main reasons: to build something cool, or to draw a paycheck. Those paychecks tend to be pretty decently sized, because we create a lot of value for the companies we work for. But how is that value quantified?
To an employer, value is probably quantified financially: are we generating more income than the cost to keep us on? This is why (I’ve read – I don’t have personal experience here) developers at a company that makes and sells software get treated better than developers making software for internal use only at a non-software company; the first group are revenue producers, while the second are operating expenses.Creative Commons by CheapFullCoverageAutoInsurance.com
The trouble is, it can be difficult to find a direct link between much of what we do and how much money is coming in. If I spend a week writing unit tests and refactoring code to reduce technical debt, I haven’t created anything new that we can sell, nor have I done anything that will let us increase the cost of our product. From a strictly code->dollars perspective, I haven’t done anything productive this week.
So if we’re not directly creating value for our company, are we creating value for our customers? By refactoring the code, I’m making it easier to add new features in the future, features that will help to better meet customers’ needs. When we create software that meets customers’ needs and wants, we are providing value. But how do we quantify this? If we have a good way to estimate the size of a new feature, then one way would be to measure how long it takes the implement the feature and how many bugs are produced; if these numbers decline over time, then either we’re getting better at developing (and thus our personal value to the company has increased) or we’ve improved our processes (or, in this case, the codebase we’re working with). So one measure of value would be the amount of (relatively) bug-free software (in terms of small, medium, large, or very large features) we can provide in a given increment of time.Creative Commons BY-SA 3.0 Nick Youngson
Of course, not all features are created equally. In an ideal world, we would be able to have our customers put a dollar value on each thing we might spend time on (a new feature, a 10% reduction in bugs, etc), sort those items to find the ones with the highest value per increment of time, and do those first; in that way we could be sure of providing the maximum amount of value. In practice, customers naturally don’t care about things like that refactoring that don’t pay off immediately but make all the other stuff easier in the long run.
So how do you quantify value in software development? I don’t think you can put a value on any given hour’s activity; software development is too much of a creative process in which one thing affects too many others. In the long run, it comes down to a binary: are we able to give our customers what they want and need at a price they’re willing to pay? If so, we’re providing them the value they desire and earning those paychecks.ommons
I heard a phrase I liked recently: software testing is ensuring goodness. [Alexander Tarlinder on Software Engineering Radio]
How do we ensure that our software is good, and further, what does good even mean? For a first approximation, let’s say that good software does what it’s supposed to.
How do we define what the software is supposed to do? That could mean it does what the design says it does, that it does what the user wants, or that it does what the user actually needs. This gives us the first few things to test against: we check that the design accurately reflects the users’ wants and needs, and that the software accurately reflects the design.
Of course, there’s a lot involved in writing software that isn’t generally covered in the design. Ideally we’ve specified how the program will react to any given class of input, but in practice users tend to do things that don’t make any sense. I had a bug recently that only appeared if the user opened a section of the page, clicked on a table row, opened a second section, opened a third section, hit the button to revert all the changes, reopened the third section, and then clicked a row in that section. There was certainly nothing in the design stating that if this particular sequence of events was to happen, the activity would not crash!
Ok, so that’s reaching a bit – of course we assume that the software shouldn’t crash (provided we’re not making a kart racing game). The design covers the expected responses to user stimuli, but we assume that it will not crash, freeze up, turn the screen all black, etc. Unfortunately, for a non-trivial piece of software the number of possible things to try quickly becomes exponential. How do we ensure that we’ve tested completely enough to have a reasonable chance of catching any critical bugs?
Finding the Bugs
Photograph of a mantis shrimp. Public domain, National Science Foundation.At some point, we have to determine how much effort to put into finding (or better yet, avoiding) bugs in our software. The more mission-critical the program is, obviously, the more time and money it’s worth investing into finding bugs and the less disruptive a bug has to be to be worth finding and fixing.
I’m a strong believer in the value of having a separate, independent quality assurance team to test the software. Testing is a completely separate skill from coding – rather than trying to build software that works, you’re trying to find all the ways that it could possibly break. So I think it’s valuable to have people skilled in the art of creative destruction, who can approach the software from the perspective of the end user, and who have the authority to stop code changes from moving forward if they believe those changes to be damaging to the quality of the code.
At the same time, there’s no guarantee that a few QAers will be able to try all the weird things that thousands of users might do once your software is out in the wild, which is why we also need code review (or PQA, programmer quality assurance). In code review we have a better chance of catching the one-time-in-a-million bugs that will never show up in testing and yet, somehow, will always pop up in the released code. One of the senior developers on my team was really good at this; I hated having him review my code because I knew he would nitpick every little thing, but I would still choose him to do PQA on my development for the same reason – he was really good at finding anything that might end up being a problem.
How to not code bugs
Speaking for myself, I’m not a fan of doing PQA – it gets boring really fast. Ironically, the better the code is the more boring PQA can be: with the junior developers there tends to be a lot of things you can make suggestions on, but when the code you’re looking at is very well done, you can spend an awfully long time examining it without finding anything wrong, and it takes an effort to get more in depth and concentrate more on finding subtle logic errors and race conditions rather than correcting bad habits and obvious errors in less developed code. Not that you don’t look for the subtle errors in the less developed code too, of course, but you’re not spending an hour looking through the code without finding anything.
On the other side of that, of course, you want to be the person writing the code where your PQAers can’t find anything to complain about. I have not yet figured out how to do this – not even close – but there are a few things that help.
Testing. Ok, this one is obvious, but it can be surprising how often someone makes a very minor change and then doesn’t go back and test afterwards. Even a change that can’t possibly break anything, often does.
Following standards. My team has a set way of doing things, and yours probably does as well. Why? Because we’ve broken stuff in the past, and figured out how to not break them the same way in the future.
Refactoring. See below.
So we’ve been doing unit testing for about the last year and a half, now. Most of the unit tests so far are in code that hasn’t really been updated a lot since the tests were written, so they aren’t yet serving one of the primary purposes of unit tests: letting the next person to work on your code (who might be you) know if he breaks it. What they are doing is making the code better.
When I’m writing unit tests for a function, sometimes I run into problems:
It’s not obvious what the function is doing. This generally means that the function (and possibly some parameters) needs to be renamed so that it’s very clear what will happen when it’s called.
The function is doing too much. In this case, I split it up into multiple functions – even when the subfunctions will only be called from one place. This gives me several functions that only do one thing, which makes it easier to verify that the logic behind each piece of functionality is correct.
The function depends on something being set prior to being called (generally uncovered by a crash when the unit test first calls it with no prep work). This is a good time to verify that under no circumstances can the function ever be called without its prerequisites ever being set (and possibly document the preconditions).
The function contains logic which is actually wrong. In this case, I’ve just uncovered a bug, and can fix it, before my code goes to testing.
Most of the time when I’m refactoring a function there aren’t actually any bugs present, yet… but conditions exist that make it easier for bugs to be inserted. By cleaning up the code, I then improve my chances of being able to make changes without introducing new bugs in the code. Further, because the code is now easier to read, not only are future changes less likely to break it but they’ll be made faster and with less frustration.
So how do we ensure goodness? Very carefully, I suppose. In my experience, the best way to do this is just to make it easy to do the right thing. Make it clear from the names what functions do, keep the code as simple and straightforward as possible, and be sure you understand exactly what the code is doing before you make changes (or, if you’ve written it, before you commit it).
Of course, having a can of RAID on hand never hurts.
Recently my friend Janie has done a series of blog posts on her disagreement with using computer science questions as a major part of the hiring process. I can agree with her, to a point.
If you’re hiring for someone to do a specific job using a specific language or framework, and the person being interviewed can demonstrate experience with and competence in that language or framework, then that’s probably as far as you need to go. You have a job that needs to be done and you’ve found someone who can do that job. Win!
I think that when the job is less well-defined is when algorithms questions can more usefully come into play. But let me back up and relate a few stories from my personal experience.
As a GTA (graduate teaching assistant) part of my job was to monitor the computer lab and help people as needed. The undergraduate classes at my school used Java; I don’t, but I grabbed a book and picked up enough of it to be able to get people unstuck. I guarantee that pretty much everyone I helped had much more experience with and knowledge of Java than I did – they were using it every week for their classes, while I’d picked up the bare minimum to be able to read it. But I was getting people unstuck because they didn’t understand how to take a problem and write a program that would solve it; they knew how to program, but they didn’t know how to think.
The class that I taught, Foundations of Computer Science, involved no programming whatsoever (and many people put off taking it, for that reason). We covered finite state machines, regular expressions, Turing completeness, that sort of thing. I can recall thinking that if I was hiring someone for just about any job, I would consider an A in that class as a strong recommendation, because it meant that you could think logically and solve problems.
When I was working on my PhD I did almost no programming; I was focused on theory. I think I wrote three programs in four years. Towards the end of that, Microsoft was doing interviews on campus, and I decided to give it a try; the interview turned out to be two questions along the lines of “Here’s a problem. Solve it, then find the fastest possible solution.” I found the problems to be reasonably straightforward (though you had to be a little creative for one of them) but the interviewer told me that most of the people he’d interviewed couldn’t even answer the first problem.
I don’t mean to suggest here that programming skills or experience are not important, only that unless the problem is very well defined, they may be less important than knowing how to figure things out. The advantage that knowing algorithms (and everything that goes with it) gives you is that you have more tools available to you; in the case of the Microsoft questions, one of the problems was very obviously susceptible to dynamic programming, and knowing big-O analysis made it easy to say “this is the best asymptotic runtime of any solution to this problem.”
My current employer has a similar philosophy. The initial test I took allowed you to use any programming language you liked; another one taught you an obscure language and then asked you to use it. Combined with a preference for people with strong academic backgrounds, they’re selecting for employees with a demonstrated ability to both solve problems efficiently and pick up new things quickly. Now I regularly use half a dozen languages at work, none of which I knew when I started, and the turnover at the company is low compared to the larger tech industry. Microsoft and Google have actually pouched half of my team over the last few years, but that’s another story..