Consider test-driving a new car, of a make and model you’re not familiar with. It’s unlikely you’ll need any instruction in how to do it: rightmost pedal makes the car go, pedal next to it makes the car stop. Even though there are many different cars, they have a reasonably consistent interface that allows most people to drive most cars.
Subclassing Car
Suppose we want to implement this in code. Let’s say I want to use a Camry object. A Camry “is a” car, so it makes sense that the Camry class inherits (possibly indirectly) from the Car class. We would never actually instantiate a generic “car” object, so Car can be an abstract class.
What methods would Car have? Two obvious ones could be ApplyGas and ApplyBrake. Maybe they’re implemented something like this:

In this case, the comments are standing in for some code that physically allows more gas into the engine or applies the brakes. This works fine….as long as every car works exactly the same way. But what happens if we have, for example, a Prius? Now stomping on the gas pedal may or may not actually be sending more gas to the engine, which means that we need to override the behavior in the derived class. More generally, for each type of car that derives from the Car class and uses different hardware, we’ll need to rewrite the methods for that car’s hardware – and if we forget, and the method tries to use hardware that isn’t there, then things can go horribly, horribly wrong.
Ok, so we’ll make ApplyGas an abstract method; now each derived class will be forced to implement it appropriately. The same will go for StartCar (do we need a key?), ChangeGear (which gears are available?), and many of the other methods, but the Car class is accomplishing our goal of ensuring that each derived class has a consistent interface.
However, we should step back and ask – what are we gaining here? We’re not sharing implementations; we simply want a consistent interface. So…maybe we should consider using an interface?
Defining an Interface
While inheritance allows us to share behavior between related objects, an interface is simply a contract that defines certain methods each class implementing that interface promises to provide. As a driver, I don’t care how each method is implemented; I simply want to know that, given an instantiation of any class which implements ICar, stomping on the gas will make me go faster and using the brake will make me slow down. I want to learn the interface, and from that, be able to handle anvy new car that might be released.
Let’s define a simple interface for car:

Here we’ve defined various methods that we’d expect to apply to any car. There’s a way to turn it on and off, which could be by means of a key (most vehicles), by the location of the key (Tesla), or some other method entirely – we don’t know what it is, just that there is one. There’s a way to accelerate and a way to slow down. We can get the current speed and we can change direction. As is standard practice, we’ve named the interface starting with a capital I.
Notice two things that none of the methods have: an access modifier and an implementation. Since an interface is just a contract, all methods are public by default – an implementing class can’t agree to implement the methods if it doesn’t know what they are! Similarly, the interface doesn’t define how any method is to be implemented, just that they must be.
Implementing the Interface
Suppose we go ahead and create a class that implements ICar:
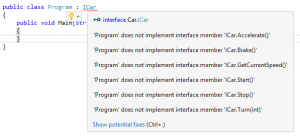
Here we’ve made the claim that this class (unhelpfully named Program – we should really choose a better name) implements ICar, but we haven’t actually provided any method definitions, which gives us the red squigglies. Hovering over ICar shows all the methods that we’re required to implement before the program will compile. This is one of the advantages of using interfaces – we can’t possibly forget to provide a custom implementation for one of the methods and end up using the default implementation without meaning to.
If we hit control-., Visual Studio will offer to implement the interface for us, either implicitly or explicitly.
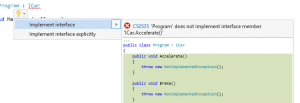
If we choose to implement the interface, then each of the required methods will be created; since all interface methods are public, that access modifier is automatically assigned. If we implement the interface explicitly, then instead of the access modifier the method is explicitly called out as being the implementation of an interface. This is important because it’s possible that our class implements several interfaces which have methods with the same signature that need different implementations; declaring which implementation the method is associated with allows us to have several methods with the name name and call the appropriate method for the interface we’re currently using.

Multiple Interfaces
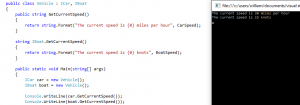
Let’s look at an example. Here I’ve added an interface IBoat which also has a GetCurrentSpeed method, and updated that method in ICar so that both methods return strings. Since I’ve implemented ICar implicitly, IBoat must be implemented explicitly (and Visual Studio will do this no matter what option I choose when I tell it to implement the new interface). I’ve renamed Project to something that makes more sense (Vehicle) and written a main() routine that creates two vehicle objects, one for each of the two classes. When I run the program, each call to GetCurrentSpeed will automatically find the correct method for its interface, and in fact the boat object cannot even see the methods which are specific to the car interface.
Programming to the Interface
You may have heard that you should program to the interface, not to the implementation. This means that if we know what interface an object implements, we don’t need to know or care what the object actually is. In our example above, we know that car implements ICar, but we don’t actually need to care that it instantiates Vehicle (as opposed to ToyotaCamry, FordTaurus, etc). If in the future we decide to change the implementation of car to be TeslaModelS instead of Vehicle, we only have to change one line of code. Because car is defined as an ICar, we can only call methods defined in ICar (or Object, which ICar inherits from) on it, and those methods are guaranteed to exist in every class that implements ICar.
Thus, although interfaces can be used as a type of multiple inheritance, their real value is in allowing components to be loosely coupled: when one part of the program changes, it becomes less likely that this will result in other parts of the program needing to change, which means less work and (hopefully) fewer errors. By restricting what we’re allowed to do (in this case, restricting objects to using only methods required by the interface), we actually make those objects more usable.



 The central thesis of the book is that modern knowledge has made the world too complex for humans to handle unaided. Take any complex profession – medicine, architecture, etc – and you find specialization and sub-specialization: there’s simply too much expertise required for anyone to be a generalist. Even within the sub-specialties, there’s so much to keep track of that it’s easy to miss a step, and that one missed step can result in a collapsed building, crashed airplane, or dead patient. We have finally advanced enough that “errors of ignorance” – mistakes because of what we don’t know – are often less important than “errors of ineptitude” – mistakes from not making proper use of what we know.
The central thesis of the book is that modern knowledge has made the world too complex for humans to handle unaided. Take any complex profession – medicine, architecture, etc – and you find specialization and sub-specialization: there’s simply too much expertise required for anyone to be a generalist. Even within the sub-specialties, there’s so much to keep track of that it’s easy to miss a step, and that one missed step can result in a collapsed building, crashed airplane, or dead patient. We have finally advanced enough that “errors of ignorance” – mistakes because of what we don’t know – are often less important than “errors of ineptitude” – mistakes from not making proper use of what we know.

 I’ve had one code reviewer who was extremely against ever using this, to the point where I replaced the one I was using with an if/else statement (at the expense of clarity) just to end the argument (knowing that I was unlikely to work with him again anyway). The conditional operator can certainly be misused; consider something like the following:
I’ve had one code reviewer who was extremely against ever using this, to the point where I replaced the one I was using with an if/else statement (at the expense of clarity) just to end the argument (knowing that I was unlikely to work with him again anyway). The conditional operator can certainly be misused; consider something like the following:{kind=link}